
作者:智信禾
时间:2020-11-23
摘要
机器学习(Machine Learning,常简称为ML)是计算机系统为了有效地执行特定任务,不使用明确的指令,而依赖模式和推理使用的算法和统计模型的科学研究。
如果有读者研究过从2000年至今的机器学习领域的专利申请数据,那么其实不难看出,近10年来关于机器学习技术的专利申请量整体是一个上涨的趋势,中国2019年在机器学习领域申请的专利数量达到42,893项(不包含未公开的专利数量),可见,机器学习逐渐成为一个研究的热门,并且机器学习也已经逐渐应用到越来越多的领域。
其实笔者自入行以来,也一直都在学习机器学习技术领域的知识,主要的学习方向在于模型的训练和模型的应用两类,而在机器学习任务中的学习方式主要包含有监督学习、无监督学习、半监督学习以及自监督学习等,那么,判断机器学习任务属于哪种学习方式的方法也很简单,即判断输入模型的数据是否有标签,如果输入数据带有标签(label),则为有监督学习;不带有标签,则为无监督;如果输入数据中仅有少量数据带有标签,则为半监督学习。由于在实践中常用的机器学习任务就是有监督学习和无监督学习,因此笔者此次也主要对这两种学习任务进行阐述。
(一)
有监督学习,有监督学习又可以分为分类(预测非数字答案,例如问答场景中的答案提取)和回归(预测数字答案,例如下一季度的商品销售量)。
有监督学习适用于样本数据有标签的情况,例如,如果要构建一个答案抽取模型,则需要收集很多问题以及问题对应的答案,将这些问题作为样本数据,并将每个问题对应的答案作为标签,输入模型进行训练,训练后获得的模型将问题和答案之间建立关联关系,因此该模型可用于答案抽取,即输入一个问题,模型即可输出这个问题对应的答案。
(二)
无监督学习,对于无监督学习,又可以进一步分为聚类、关联、降维(投影,特征选择)、以及特征提取。
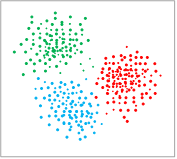
无监督学习适用于样本数据没有标签的情况,例如,如果要构建一个用于划分用户消费类型的模型,则可将多个用户的历史消费记录作为样本数据输入模型进行训练,模型训练过程中,可以基于样本数据中的共享特征将样本数据划分为不同的集群,在模型应用阶段,在输入一个用户的消费信息后,模型可根据消费信息中的特征将用户划分到对应的集群,从而确定用户的消费类型,具体的划分效果示意图如下图所示,无监督学习获得的模型可以将存在共同特征的数据划分至同一集群。
除训练数据存在区别外,评估方式同样存在区别,有监督学习的分类评估指标包括:准确率、召回率、精确率、F1指标,回归评估指标主要包括:平均绝对误差(MAE)、均方误差(MSE)、R-squared;而无监督学习的聚类评估指标包括:凝聚度、分离度、轮廓系数。
Tips:
由于在实际应用中,进行专利申请的技术方案大多是对现有技术的改进,那么在机器学习领域的技术方案大致可以分为三类,分别为:对模型训练阶段的改进、对模型应用阶段的改进以及对模型架构的改进。在申请文件的撰写过程中,代理人可以根据方案的具体改进点确定专利所要重点保护的权利范围。
如果是对训练阶段的改进,则可重点写模型训练部分(模型内部结构的改进、样本数据的筛选或损失函数的改进等),之后将模型的应用通过从属权利要求或单独的独立权利要求进行布局即可。
如果是对模型应用阶段的改进,则可重点写应用部分(待处理数据的采集、筛选等),对于训练过程,则可以放在从属权利要求或者说明书中。
而对于模型架构的改进,由于其具有一定的创造性,因此,为了能够对技术方案更清楚的进行解释说明,代理人在撰写过程中,可以在附图中增加模型架构改进后的结构示意图,以此来直观的体现方案的改进点。
此外,需要注意的是,代理人在写模型的训练过程时,可以适当将技术特征与应用场景相结合,避免权利要求过于上位而被认为是对机器学习的通用训练算法的改进,并非是利用自然规律的技术手段。